Magenta RealTime 2:低延迟音乐模型如何变成可演奏音源
围绕 Google Magenta RealTime 2 的开放权重路线,解析 40ms 帧级自回归、约 200ms 端到端控制延迟、SpectroStream 离散音频 tokens、MusicCoCa 风格嵌入、MIDI 帧对齐条件注入,以及 Base 2.4B / Small 230M 双模型在实时音乐工作流中的取舍。
技术解析 / Google Magenta
当前很多神经音乐生成系统仍采用“批处理渲染”:用户输入提示词,服务器离线计算数十秒,最终返回一段已经封闭的音频。它适合快速拿到草稿,却切断了创作者和模型之间的实时反馈。实际演奏会连续发生按和弦、推滤波器、改变节奏等动作,伴奏也要跟着手势转向。
Magenta RealTime 2(MRT2)正是朝这个方向推进的开放权重模型。Google Magenta 把它定义为面向 on-device streaming generation 的 live music model:它能够在低延迟控制下连续生成音乐音频,并同时接受文本提示、音频风格示例和 MIDI 输入。相较前代,官方发布页给出的核心变化非常明确:模型帧长从 2 秒降到 40ms,控制延迟约 200ms,并通过 frame-level autoregression 与 frame-aligned conditioning 把音乐生成从“块级生成”推进到“帧级控制”。
这条神经音频管线可以拆成四个关键问题:SpectroStream 如何把 48kHz stereo 音频压缩为可预测 tokens,MusicCoCa 如何把文本与音频风格放入共同嵌入空间,Decoder-only Transformer 如何在每个 40ms codec frame 中融合历史音频、MIDI 状态与风格条件,以及 causal sliding window attention 如何让持续生成在内存和时延上可控。
1. 从批处理渲染走向实时神经乐器
MRT2 接在两条已经成形的路线后面:研究侧的 Magenta RealTime,以及云端交互产品 Lyria RealTime API。前代已经证明音乐模型可以连续生成并接受风格控制,但它仍按约 2 秒音频块做 chunk-wise autoregression。模型先积累一整块上下文,再输出下一段声音;当演奏者按下 MIDI 键、改变风格提示或换入新的音频参考时,控制信号要等到当前块结束才会听见。
MRT2 没有推翻 SpectroStream 与 MusicCoCa 的底座,变化集中在生成主干和控制粒度。Decoder-only Transformer 改为 frame-wise autoregression,每个 SpectroStream frame 只有 40ms;模型生成每一帧时都会重新读取 MIDI、风格 embedding 和历史音频 tokens。控制延迟从前代约 3 秒缩短到约 200ms,来源并非一句“模型更快”,而是控制信号从两秒一次进入系统,变成每 40ms 都有机会改变下一帧。
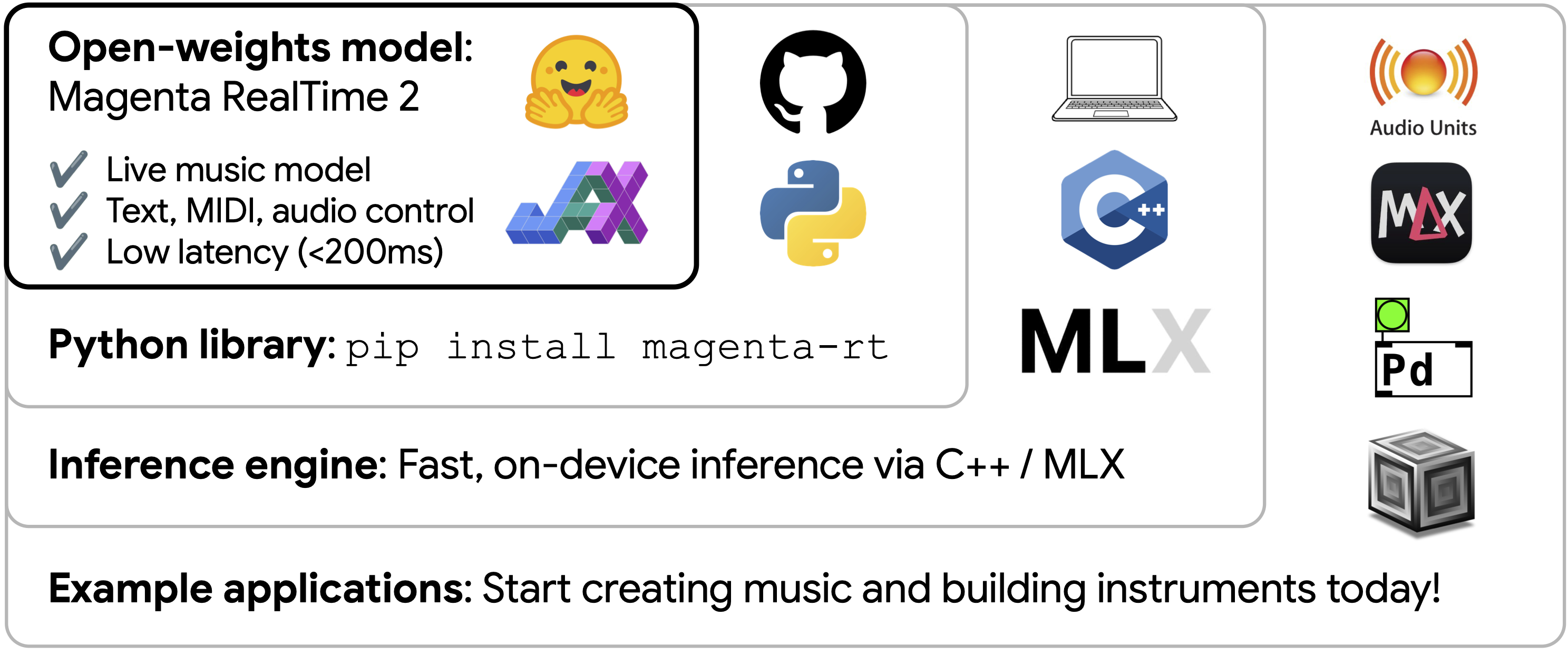
这次代际变化也把云端演示与本地工具分开。Lyria RealTime API 展示了托管式实时生成,MRT2 则公开权重、Python 推理库、MLX C++ 引擎、DAW 插件和独立应用示例。音乐人面对的不再只是一个持续输出音频的服务接口,还可以把模型嵌入自己的宿主、控制器和现场系统。

2. 时频底座:三元协同的神经音频管线
MRT2 由三个核心组件组成:SpectroStream、MusicCoCa 和 Decoder-only Transformer LLM。SpectroStream 负责把高保真音乐音频转成离散 tokens;MusicCoCa 负责把文本描述和音频示例映射到共同风格空间;LLM 则在历史音频 tokens、MusicCoCa 风格 tokens 和 MIDI tokens 的条件下生成下一帧音频 tokens。这套组合让 MRT2 同时吃下文本、音频和 MIDI,而不是只围绕单一 prompt 工作。
2.1 SpectroStream:高保真离散音频编解码器
SpectroStream 是 MRT2 的声学底座。官方模型卡写明,它把 48kHz stereo 音乐音频转成离散 tokens:25Hz frame rate、64 RVQ depth、10 bit codes、16kbps。这个压缩表示把原始波形中庞大的连续采样点,变成结构化的 token 序列,让 Transformer 面对的是“音乐语言”而不是直接预测每个采样点。
2.2 MusicCoCa:文本与音频风格的共同潜空间
MusicCoCa 是经过对比学习训练的风格表征模型。它可以接收 16kHz mono 音乐音频,也可以接收 “heavy metal”“disco funk” 这样的文本风格描述,并输出 768 维 embedding;这个 embedding 会被量化为 12 层 RVQ、10 bit codes,作为全局风格条件输入生成主干。也就是说,MRT2 的风格不只来自文字,还可以来自一段参考音频。
2.3 Decoder-only Transformer 主网
MRT2 的主生成器是 Decoder-only Transformer。官方模型卡列出两个配置:Base 版为 2.4B 参数、20 层;Small 版为 230M 参数、12 层。Base 更偏向质量上限,Small 更偏向可运行门槛。与第一代 chunk-wise 路线相比,MRT2 的关键变化是 frame-wise autoregression:每一步只生成一个 codec frame 的 12 个 RVQ tokens。
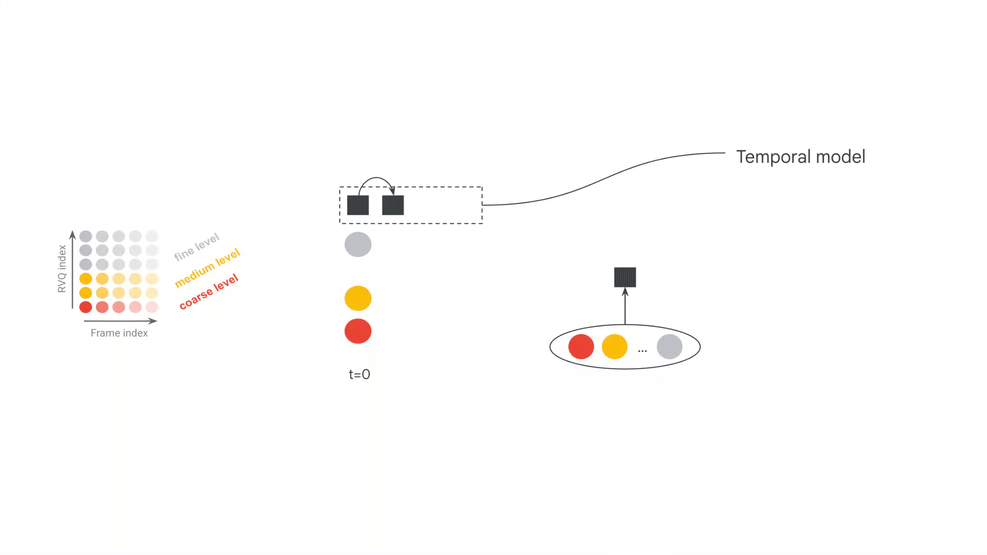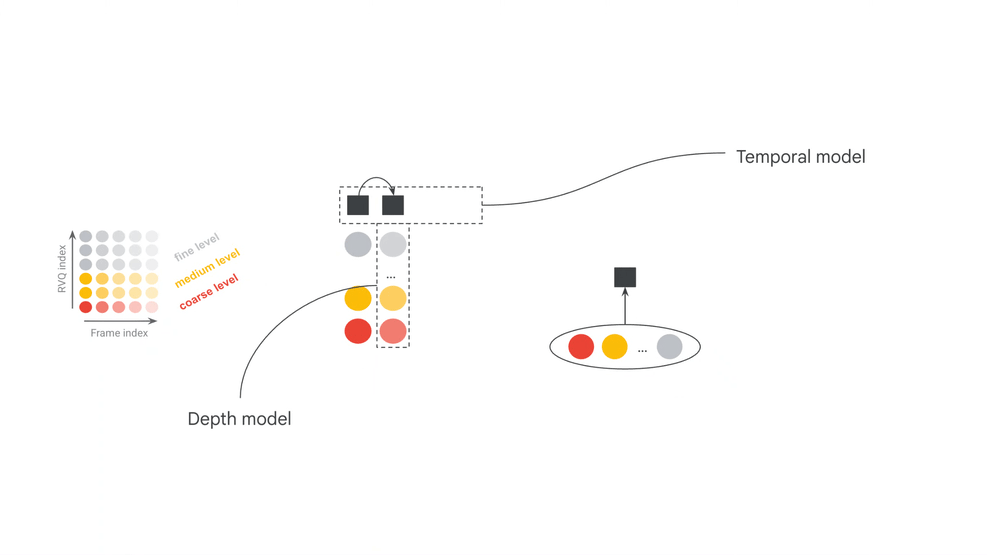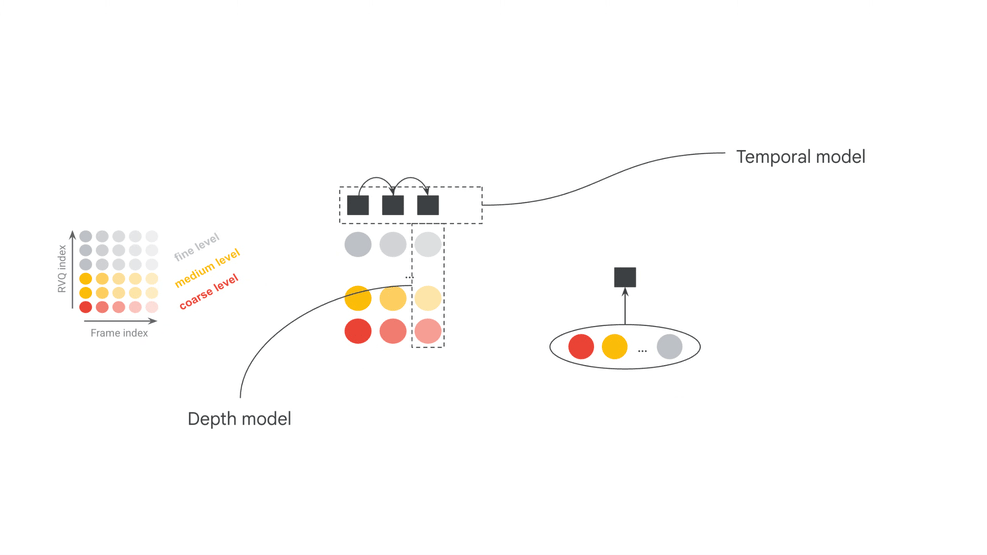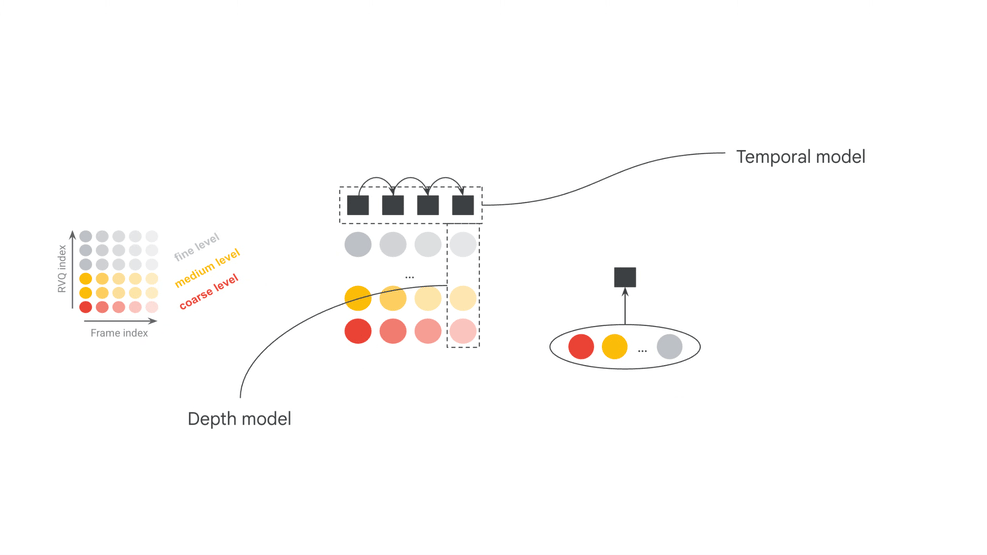
3. 核心机制:帧级自回归与多模态条件对齐
MRT2 把延迟压低的核心数学结构,是帧对齐条件注入(Frame-Aligned Conditioning)。在每个时间步 t,也就是一个 40ms 的 codec frame 内,Decoder-only Transformer 会在同一个统一注意力机制下读取当前帧的 MIDI 条件、MusicCoCa 风格标记以及历史音频上下文,然后生成当前帧的 RVQ tokens。
其自回归条件概率分布可以抽象为:
其中,A_t 表示当前正在生成的音频令牌帧,M_t 是当前帧捕获到的 MIDI 条件向量,S 是 MusicCoCa 导出的风格标记,A_context 表示历史音频上下文。MRT2 每生成一帧都会重新读取当前演奏状态,MIDI、文本风格和音频上下文因而持续参与发声。
3.1 128 维 Multihot MIDI 状态矩阵
为了让模型实时听懂人类按下的琴键,MRT2 在每一帧中动态注入一个 128 维 multihot 音高向量。针对每个 MIDI pitch 的生命周期,官方模型卡给出四态编码:
| 0 | Off(音符关闭) |
| 1 | Sustain(持续保持) |
| 2 | Onset(音符刚按下的瞬态触发) |
| 3 | Sustain or onset(复杂延音混合,由模型决策) |
模型在每一步前向传播时都会读取当前 M_t 状态,演奏者在键盘上的细小音符变化也能进入下一个 40ms frame。离线 prompt-to-track 工具通常只在生成前读取一次条件;MRT2 把 MIDI 保持为整段生成期间的连续控制信号。
4. 长程生成:因果滑动窗口与注意力汇聚
音乐流式生成理论上可以无限延长。如果自注意力不断向后扩展,计算复杂度和 KV cache 显存占用会不断增长,演奏几分钟后系统就会被历史上下文拖垮。MRT2 通过 causal sliding window attention 限制每层的局部上下文:Base 使用 25 frame(1s)windowed attention,Small 使用 41 frame(约 1.6s)windowed attention;两者通过多层堆叠获得 20s effective receptive field。
这个设计保留了足够的局部音乐上下文,同时把单步计算开销控制住。模型不需要记住整场演出的每一个 token,仍能维持短期节奏、音色和和声关系。对实时系统来说,这种“有限窗口 + 层级感受野”的取舍比无限上下文更实际。
官方模型卡还提到 learnable attention embeddings,用于提升任意时长生成和 context eviction artifacts 的泛化表现。发布页把这类问题描述为长上下文生成中的 ringing、feedback 等伪影。当滑动窗口不断丢弃旧上下文时,模型需要额外的稳定锚点,避免声音突然漂移、反馈尖叫或尾音失控。
5. 工程实现:MLX C++ 推理引擎与 Apple Silicon 音乐工作流
MRT2 的工程部分同样关键。官方 GitHub 仓库提供 Python 推理库 magenta-rt,支持 JAX 和 MLX backends;同时提供 C++ inference engine magentart::core,用于 Apple Silicon MacBook 上的高效流式音频生成。发布页说明,团队使用 MLX 将基于 SequenceLayers 实现的模型编译成 .mlxfn 容器文件,其中包含权重和静态计算图;C++ 引擎加载该文件后,负责模型状态、音频缓冲/重采样和 MIDI 输入。
硬件边界要按官方运行条件写准。Small(230M)支持在任何 Apple Silicon Mac 上实时流式运行,包括 Air 机型;Base(2.4B)实时运行需要更强的 Pro/Max 级芯片。两种模型都可通过 Python library 在 Apple Silicon Mac 或 NVIDIA GPU 上做 offline non-real-time inference。普通 Mac 能实时运行的是 Small,不能由此推导 Base 也能在所有电脑上实时运行。
这种工程取舍让 MRT2 不只是一个研究 checkpoint。GitHub 仓库列出了 AUv3 DAW 插件、standalone macOS app、note control app 和 prompt-space exploration app 等示例。对音乐软件开发者来说,这些示例比单张模型卡更重要:它们展示了如何把模型塞进宿主、插件、控制器和现场系统,而不是停留在 notebook 里生成一段 wav。
6. 公开指标与主流神经音乐模型对照
MRT2 当前公开资料的强项集中在结构参数、延迟口径、输入输出能力、训练数据和运行边界。官方模型卡说明,技术报告和完整评测结果将后续发布;因此这张对照表聚焦已经公开、可以相互印证的工程维度,而不是把尚未发布的主观音质分数提前写成排行榜。
| 指标维度 | Magenta RealTime 2 Base | Magenta RealTime 2 Small | 前代 Magenta RealTime / Lyria RealTime 路线 | 常见离线 prompt-to-track 模型 |
|---|---|---|---|---|
| 单步处理粒度 | 40ms frame-level autoregression | 40ms frame-level autoregression | 前代 frame size 约 2s | 通常按完整片段或长块离线生成 |
| 控制延迟 | 官方发布页约 200ms | 官方发布页约 200ms | 约 3s 量级,MRT2 官方称降低约 15 倍 | 取决于云端排队和生成长度,通常不面向实时演奏 |
| 控制输入 | 文本、音频示例、MIDI | 文本、音频示例、MIDI | 文本和音频风格控制为主 | 多以文本 prompt 和少量结构参数为主 |
| 音频表示 | SpectroStream,48kHz stereo,25Hz tokens,64 RVQ depth | SpectroStream,48kHz stereo,25Hz tokens,64 RVQ depth | 同属 codec language model 路线 | 各家不一,通常不公开完整 codec 细节 |
| 模型规模 | 2.4B 参数,20 层 | 230M 参数,12 层 | 前代公开口径不同 | 多为闭源或仅公开部分规格 |
| 运行位置 | Apple Silicon Pro/Max 级芯片可实时;也可离线推理 | 任何 Apple Silicon Mac 可实时 | 前代要求更高算力 | 多依赖云端服务 |
| 创作定位 | 实时演奏、风格引导、DAW/应用集成 | 更轻量的实时实验和本地应用 | live music model 早期路线 | 一次生成完整歌曲或片段 |
7. 边界:器乐、非词汇化人声与责任使用
MRT2 的用途边界同样清楚。模型卡写明,它面向 real-time generation and steering of instrumental music;训练数据约 7.1 万小时,主要是 stock music,且 mostly instrumental。带特定提示时,模型可能生成一些 vocal sounds and effects,但这些声音通常是 non-lexical,也就是非词汇化的人声效果,而不是稳定歌词演唱。
因此,MRT2 更适合器乐、纹理、伴奏、互动音乐、游戏配乐、装置艺术、live coding 和音乐教育探索。完整歌曲自动生成、稳定歌词演唱、商业母带级混音或可直接发行的成品制作,并不是它当前公开资料中的核心承诺。Google 的模型卡也明确强调责任使用:不得生成侵犯他人权利或版权内容的输出,输出的后续使用由用户自行负责。
MRT2 的关键词是 continuous generation 和 low-latency control。它适合被演奏和引导,而不是只被提示词命令。
官方模型卡强调 instrumental music。人声效果存在边界,更接近非词汇化声音与音效,而不是稳定歌词演唱。
开放权重和 MLX/C++ 引擎让插件与本地创作软件集成更现实,但硬件、音频接口和缓冲仍会影响体验。
代码与权重开放不等于可以生成侵权内容。模型卡对版权和输出责任有明确约束。
结语:让音乐生成回到演奏者手里
AI 音乐生成的上半场,核心是让模型理解文字、风格和长篇结构;Magenta RealTime 2 代表的方向,则是把神经音乐模型重新放回时间轴。40ms 帧级自回归、MIDI 帧对齐条件注入、SpectroStream 离散音频 tokens、MusicCoCa 风格空间、causal sliding window attention 与 MLX C++ 推理引擎,共同把一个大型生成模型压缩进可实时控制的音乐系统。
MRT2 把模型做成了一件可连续操控的神经乐器:它持续发声,接受 MIDI 手势和风格条件,也能进入 DAW、插件和现场应用。开放权重与本地推理工具把神经音乐生成从云端批处理带进演奏时间轴,每一次按键都可能改变接下来的声音。