模型新闻 / ChordEdit
ChordEdit:一站式低能量传输,让文本图像编辑更接近实时体验
摘要
ChordEdit 是 Liangsi Lu、Xuhang Chen、Minzhe Guo、Shichu Li、Jingchao Wang 和 Yang Shi 等作者提出的 CVPR 2026 图像编辑论文。它讨论的是一个看似简单、实际很难的问题:既然 SD-Turbo 这类 one-step 文本生成图像模型已经能够很快生成图像,为什么把现有 training-free 图像编辑方法压缩到一步之后,结果反而容易变形、破坏背景,甚至让不应该变化的区域也失去一致性?
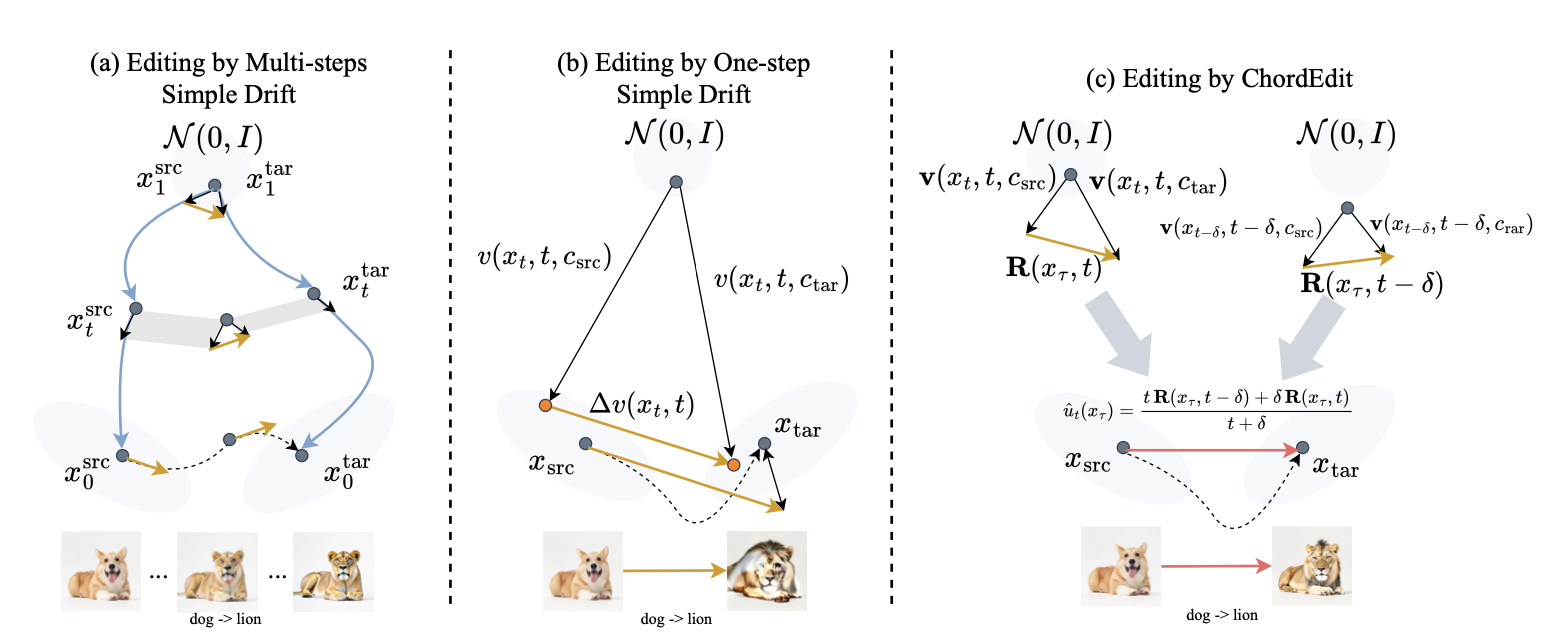
论文给出的答案不是简单地说“一步太少”,而是把失败原因定位到编辑方向本身。直接用 source prompt 和 target prompt 的漂移差分来构造编辑方向,会得到一个高能量、不平滑、方差较大的控制场。多步扩散过程中,这种不稳定信号还有可能被多次迭代和平均过程缓冲;在 one-step 模型里,它会被一次性放大,直接表现为物体扭曲、背景破碎和额外伪影。
ChordEdit 把编辑重新表述为源提示分布到目标提示分布之间的动态最优传输问题,并提出 Chord Control Field:一个经过时间加权平滑的低能量编辑场。它的目标不是让模型“凭感觉更会修图”,而是让单次大步积分的方向更稳定、更少破坏原图结构。在 TelkNet 中,用户上传图片,填写 source prompt 和 target prompt,使用与官方演示一致的公开参数运行,最终获得 PNG 编辑结果。
官方项目图:ChordEdit 展示了物体、属性、季节等语义变化,同时尽量保持非编辑区域不被破坏。
问题背景:快生成不等于快编辑
过去几年,扩散模型和蒸馏模型给了大家一个强烈预期:如果一个模型可以一步或少数几步生成图像,那么编辑也应该变得即时。SD-Turbo、SwiftBrush-v2、InstaFlow 等 fast T2I backbone 都在把图像生成推向交互式体验:用户改一句话,系统马上反馈新的视觉状态。但真实图像编辑比重新生成一张图更苛刻。它不只要满足新提示词,还要保留原图里不该变化的结构、身份、背景和构图。
这正是 one-step 编辑最困难的地方。多步编辑器可以在多个 denoising step 中逐步修正方向;inversion-based 方法可以先把源图像重建到 latent 轨迹上,再沿轨迹编辑;few-step 方法可以牺牲一些延迟换取更多纠错机会。one-step training-free 编辑器没有这种缓冲空间。如果唯一的一步方向本身不稳定,输出几乎没有第二次修正机会。
ChordEdit 论文用“场”和“能量”的语言描述这种失稳。在朴素漂移编辑中,模型分别在源提示和目标提示条件下被查询,然后通过两个漂移场相减近似编辑方向。在蒸馏后的 one-step 模型里,这些场对提示词可能高度非线性。相减得到的方向会突然变大、变抖,最终让单次积分产生可见错误。
这个解释对产品使用很重要,因为它说明“少走几步”不是全部答案。一个工具可以很快,但如果不能保留输入图像,它仍然不好用。真实用户关心的不只是目标语义是否出现,还关心原图是否仍然像原图。把马变成独角兽时,背景不应被重建;把秋天变成春天时,道路和空间关系不应被随意改写。ChordEdit 关注的正是这种平衡。
官方方法图:朴素单步方向高能量且波动明显,Chord Control Field 则通过时间平滑获得更稳定的可观测编辑场。
ChordEdit 在概念上改变了什么
ChordEdit 的核心转变,是不再把编辑简单看成两个提示条件下的向量相减,而是追问:从源提示分布移动到目标提示分布时,哪一条低能量路径更适合真实图像?论文借用了动态最优传输视角。直观地说,在许多可能的传输场中,能量更低、变化更平滑的路径通常更不容易制造剧烈偏移。
从实现角度看,ChordEdit 不要求重新训练底层文本生成图像模型,因此是 training-free;不要求对每张输入图像执行额外反演,因此是 inversion-free;它通过查询模型的 velocity、noise prediction 或等价可观测场来构造控制方向,因此也被作者称为 model-agnostic。这里的 model-agnostic 不是说任何模型、任何图片都一定同样表现,而是说方法形式可以适配多种兼容的快速 T2I 参数化方式。
关键对象是 Chord Control Field。它不使用某一个瞬时时刻的漂移差分,而是在一个短时间窗口内做加权平均。这个操作像一个时间平滑器,把抖动、过激的编辑信号变成更低能量的方向。用更直白的话说,它把“太冲、太急、太容易改坏背景”的信号,调成一条更平稳的 chord,让输出朝目标语义移动,同时尽量少破坏原图。
论文还讨论了 proximal refinement。传输部分偏向一致性和保真,refinement 可以提升目标语义强度。这种拆分很实用,因为图像编辑经常同时需要两件事:原图要保住,变化也要足够明显。只强调保真会让编辑不够强,只强调目标语义又会让背景和身份漂移。
为什么 Training-free 和 Inversion-free 很重要
训练过的一步编辑器可以很快,但它可能依赖额外模型、专用反演网络、固定 backbone 或受限数据分布。对研究原型来说这可以接受,但对可移植的工具体验来说成本更高。training-free 的吸引力在于可以直接利用已有模型;inversion-free 的吸引力在于不需要先为每张图片花时间重建源图。
ChordEdit 把目标放在一个很窄但有价值的位置:one-step、training-free、inversion-free 同时成立。多步 training-free 方法可以靠多次迭代平均掉不稳定;反演方法可以更强地锚定源图;训练式方法可以学习专门修正。ChordEdit 则试图保留 training-free 的可移植性,同时恢复足够稳定的实时编辑效果。
这也是 TelkNet 集成时没有把它做成普通 image-to-image 包装的原因。工具保留 source prompt 和 target prompt,因为方法本来就需要比较源条件和目标条件;保留 seed、n_samples、t_start、t_end、t_delta、step_scale,因为这些是官方演示中有实际意义的控制项。页面只暴露官方公开参数,不增加与方法无关的额外滑块。
论文分数应该怎样读
ChordEdit 在 PIE-bench 上评估,并与多步、少步和一步编辑方法对比。这里不应该只看一个“总分”。背景一致性可通过 PSNR、MSE 等指标理解;目标语义对齐可参考 CLIP-Edited;速度和显存占用则用于判断实时交互是否可行。论文主张的是平衡:在很低步数下保持足够快,同时尽量兼顾保真和目标语义。
官方表格中,ChordEdit(SD-Turbo)报告 PSNR 22.20、MSE 6.84、LPIPS 128.25、CLIP Whole 25.58、CLIP-Edited 22.96、Step 1、NFE 2、Runtime 0.38s、VRAM 6988 MiB。对照项中,FlowEdit(SD3)报告 CLIP Whole 26.64、CLIP-Edited 23.69,但 Step 33、Runtime 7.22s、VRAM 17140 MiB;SwiftEdit(SwiftBrush-v2)报告 Runtime 0.54s、VRAM 15060 MiB;TurboEdit(SDXL-Turbo)报告 Runtime 2.69s、VRAM 13826 MiB。把这些数字放在一起看,ChordEdit 的优势不是单个指标全部第一,而是在一步编辑、低延迟和较低资源占用之间取得实用平衡。
消融实验更能说明方法价值。在不使用 proximal refinement 的设置下,Chord field 更强调保留:论文报告 Chord 变体 PSNR 23.89、CLIP-Edited 21.87,而朴素场在相同设置下为 PSNR 21.89、CLIP-Edited 20.83。加入 refinement 后,语义强度进一步提升:SD-Turbo 上,朴素基线从 PSNR 21.38、CLIP-Edited 21.96,提升到 ChordEdit 的 PSNR 22.20、CLIP-Edited 22.96。
跨模型实验也值得注意。论文在 InstaFlow、SwiftBrush-v2 和 SD-Turbo 上都报告了优于 naive baseline 的结果。例如 SD-Turbo 上,PSNR 从 21.38 提升到 22.20,CLIP-Edited 从 21.96 提升到 22.96。这支持作者关于 model-agnostic 的说法,但仍然要谨慎理解:不同图片、不同提示词和不同 seed 会改变实际输出,benchmark 结果不能替代逐次编辑的人工判断。
官方能量可视化:论文把高能量朴素场与伪影、背景破坏联系起来,并展示 ChordEdit 生成的编辑场更低能量。
在 TelkNet 中怎样使用
使用流程很直接:上传 JPEG、PNG 或 WebP 图片;描述原图内容;描述希望得到的目标编辑结果;保留或调整官方参数;提交任务;完成后下载 PNG 结果。工具面向的是文本引导图像编辑,所以提示词质量会显著影响输出。
公开参数与官方演示保持一致。用户需要填写 source_prompt 和 target_prompt;seed 默认 42,与官方演示默认值一致;传输控制项包括 t_start、t_end、t_delta 和 step_scale;样本数使用官方 n_samples 的 1 到 16 范围。TelkNet 默认把 n_samples 设为 16,因为产品要求优先使用最高质量设置,用户也可以为了更快试验而降低它。
更稳定的使用建议
把 source prompt 写成原图 caption
ChordEdit 需要源提示,因为它估计的是源条件到目标条件之间的传输场。source prompt 应描述已经存在的图像,而不是只写想要的变化。
target prompt 聚焦一个清晰变化
好的目标提示会说明希望改变的语义,同时避免把整张图完全重写。比如“黄色出租车在雪地里”通常比同时要求多个无关变化更稳定。
用 seed 做对比
固定 seed 更容易比较参数差异。需要探索同一编辑的不同可能版本时,再切换 seed。
最终结果使用最高样本数
TelkNet 默认使用官方范围内最高的样本数。快速预览时可以降低;需要最终图时,建议保留默认最高质量设置。
它没有承诺什么
ChordEdit 很快,也很有研究价值,但它不是万能照片编辑器。它不能理解提示词没有写出的意图,不能保证每一个细小身份线索、标志、人脸或文字都完全不变,也不能消除模型偏见、幻觉或提示歧义。论文解决的是 one-step 控制场过于高能量、过于不稳定的问题,而不是把所有图像编辑风险都消除。
因此使用时要区分三层:论文性能、官方演示行为和真实工具结果。论文性能来自固定 benchmark;官方演示展示作者希望暴露的参数;真实结果取决于输入图片、提示词、seed 和参数选择。这三层是相关的,但不能完全等同。
对用户来说,最实用的理解是:ChordEdit 让实时文本引导编辑更接近可用状态,因为它针对 one-step 控制场失稳这个具体问题给出了低能量传输解法。它尤其适合需要明显语义变化,同时又希望保留背景、结构和主体身份的场景。