Google Magenta RealTime 2: when a music model becomes a playable instrument
A source-scoped technical overview of MRT2's 40ms frame-level autoregression, low-latency MIDI/text/audio control, 2.4B/230M model split, SpectroStream codec path, MusicCoCa style embeddings, and the practical boundary between live steering and one-shot song generation.
Model News / Google Magenta
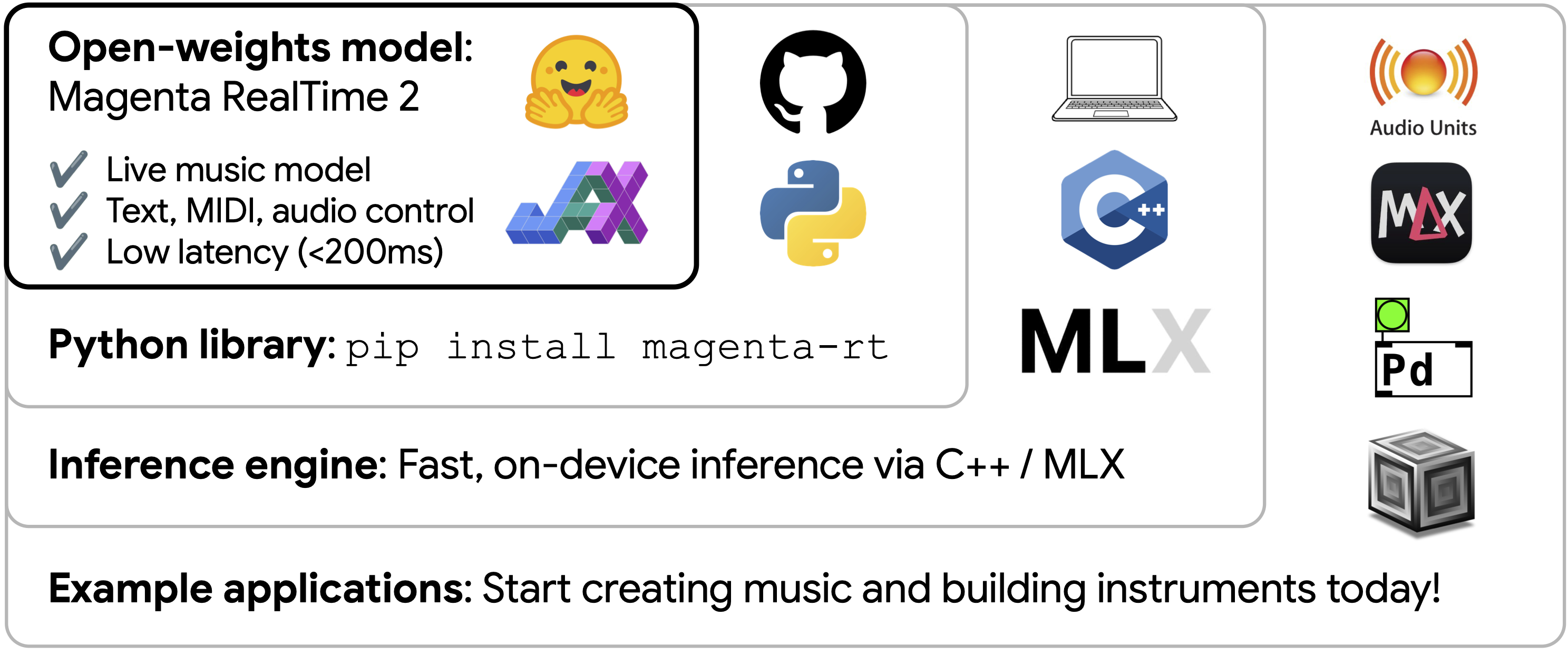
Google Magenta RealTime 2 (MRT2) is not a conventional "type a prompt, wait for a complete track" music generator. Google's release frames it as a combination of an open model, real-time inference engine, and example applications: a 2.4B-parameter base model, a 230M-parameter small model, SpectroStream audio codec, MusicCoCa style representation, MIDI/text/audio control, and a local real-time music generation experience.
This updated article adds official Google figures and model-card evidence to explain MRT2's distinctive position. It is not trying to replace arranging, mixing, or full-song production. It pushes music models toward playable, controllable, DAW-friendly, live interaction. In practice, it reads more like a real-time collaborator than an offline song machine.
From Magenta RealTime and Lyria RealTime API to a playable local model
MRT2 follows two earlier branches of the same research program: the Magenta RealTime model and the hosted Lyria RealTime API. Those systems established continuous generation and steerable musical style, but the prior model used chunk-wise autoregression with a roughly two-second frame. A note, style change, or new audio reference could not affect the sound until the current chunk finished.
MRT2 keeps SpectroStream and MusicCoCa, then changes the generating backbone to a decoder-only Transformer with frame-wise autoregression. A frame is now 40 ms, so MIDI state, style tokens, and audio context are read again for each new frame. Google's reported control latency moves from roughly three seconds to about 200 ms. During the two-second interval that previously produced one chunk, the new model has fifty opportunities to redirect the sound.
The release also separates a hosted demonstration from a model musicians can place inside their own tools. Lyria RealTime API showed interactive generation as a service; MRT2 publishes weights, a Python library, an MLX C++ engine, DAW examples, and standalone applications for on-device use. It can sit inside a performance setup, game soundtrack system, or installation without reducing the interaction to prompt, wait, and download.

Technical Evidence: Not Just A Bigger Model
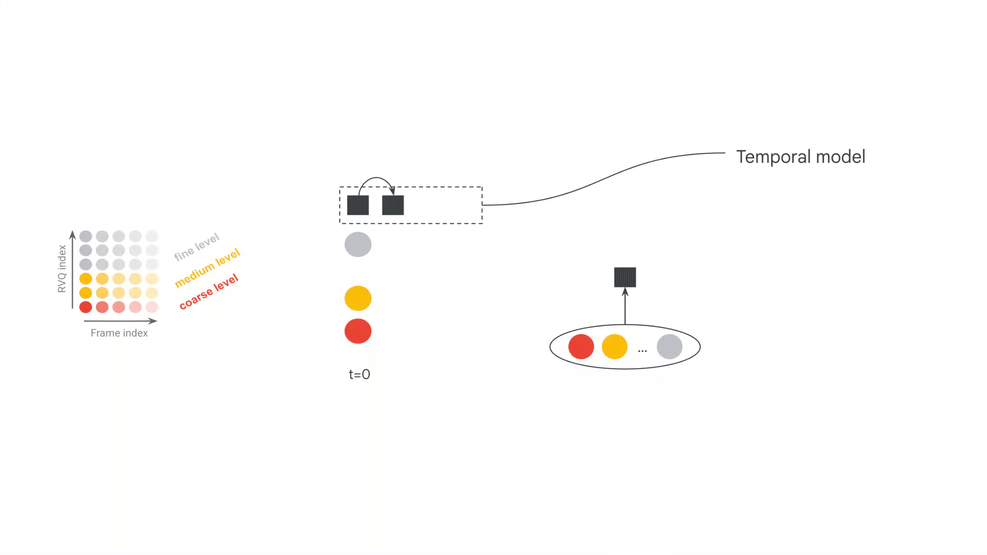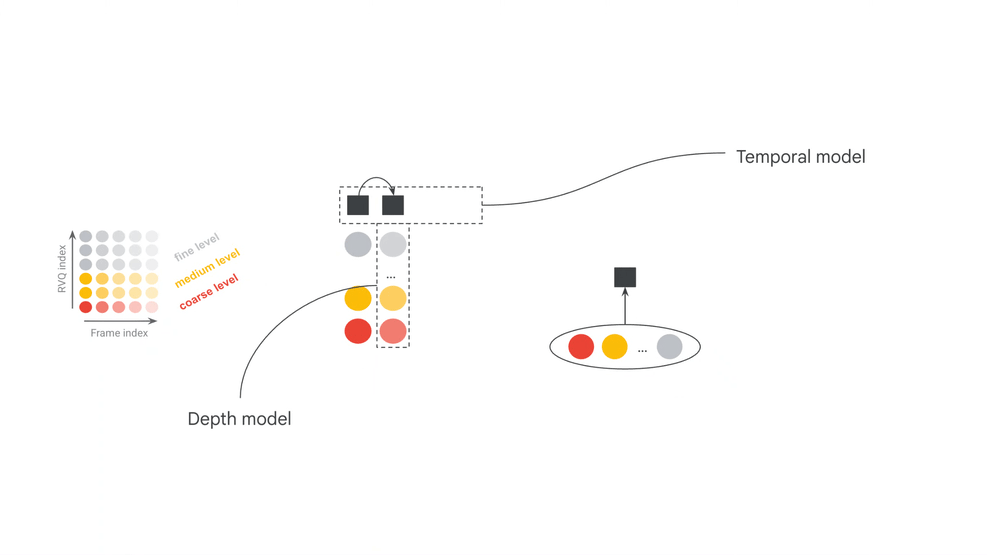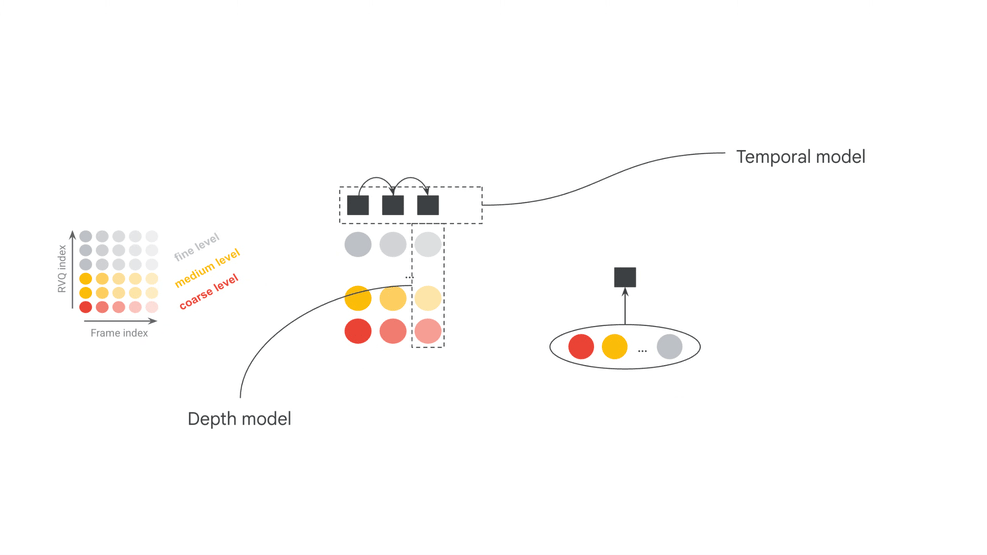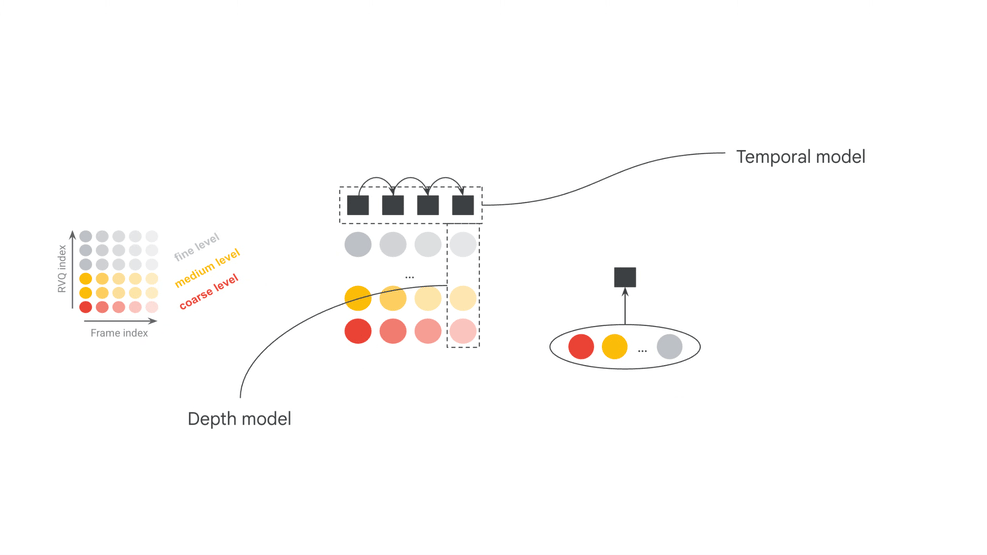
The official model card separates MRT2 into three core components: SpectroStream, MusicCoCa, and a decoder-only Transformer LLM. SpectroStream is a discrete audio codec that converts 48kHz stereo music audio into tokens. MusicCoCa maps text and music audio into a shared embedding space. The LLM generates the next audio frame given context audio tokens, MusicCoCa style tokens, and MIDI tokens.
This structure explains why MRT2 can accept text, audio, and MIDI at the same time. Text describes style, audio provides sonic or musical reference, and MIDI supplies performance-state control. The inputs are not simply concatenated; they occupy different roles in the real-time generation loop.
The two official model configurations are also revealing: a 2.4B-parameter base model and a 230M-parameter small model. The base model leans toward quality, while the small model lowers the local-running bar. The model card also lists 25-frame (1s) windowed attention for base, 41-frame (~1.6s) windowed attention for small, and a 20s effective receptive field for both. This is continuous generation with bounded context, not offline reasoning over an entire song.
What Low Latency Actually Means
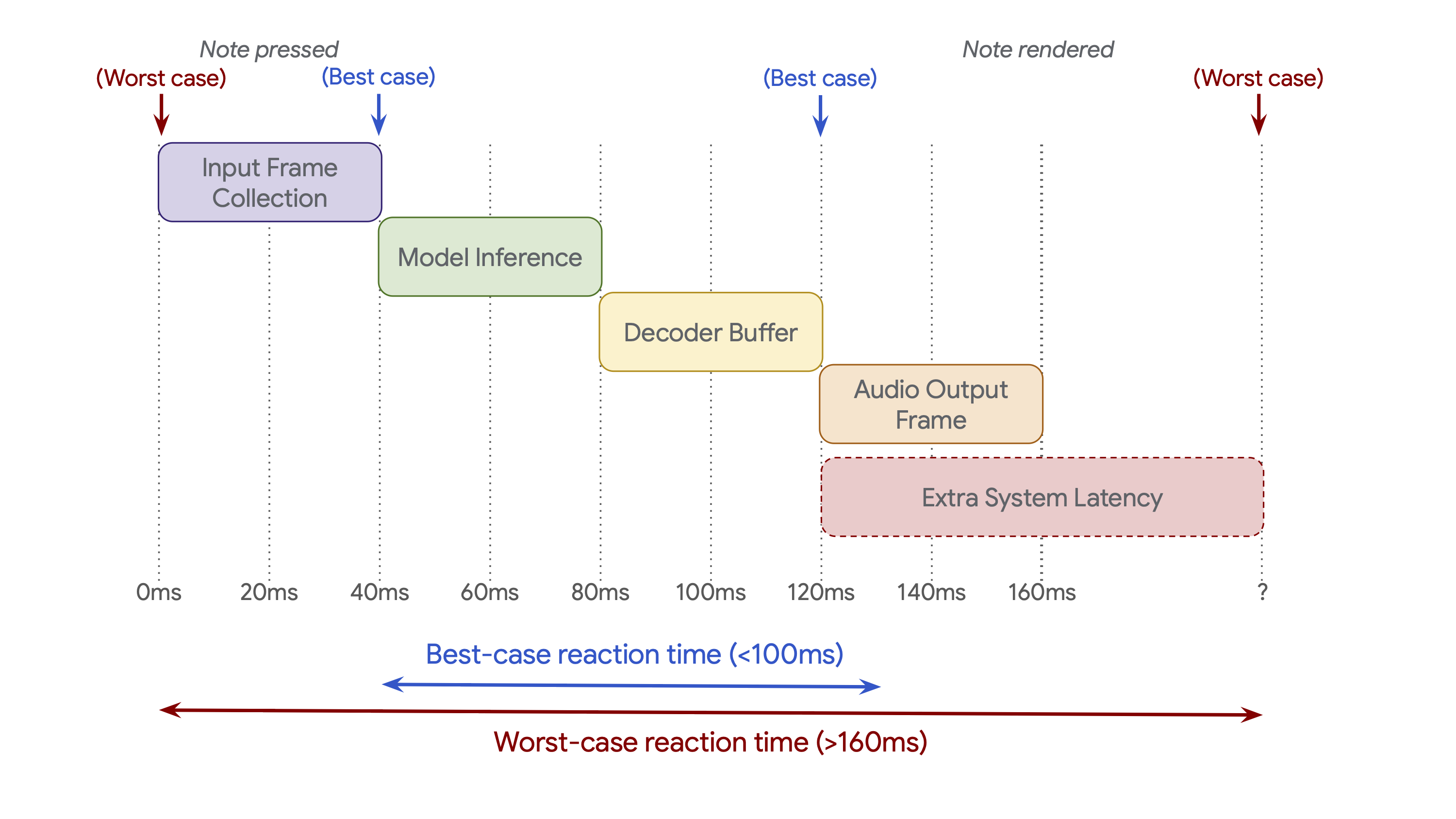
One of Google's headline changes is reducing the model frame size from 2s to 40ms compared with the previous generation, and reducing control latency from roughly 3s to about 200ms. That number is compelling, but it needs the official boundary: end-to-end reaction time is not only model inference. It also includes input buffers, output buffers, audio interfaces, host software, and external components.
For musicians, ~200ms is not the near-instant response of a hardware keyboard or drum trigger. But it is enough to move a model from "offline generator" to "interactive system." MRT2 is better read as a fit for style morphing, accompaniment extension, texture response, live coding, installations, and game music than as a replacement for millisecond-accurate drum machines or piano instruments.
How It Differs From One-Shot Song Generation
| Dimension | Magenta RealTime 2 | Common prompt-to-track generators | Practical impact |
|---|---|---|---|
| Interaction rhythm | Listen, perform, adjust, and keep generating. | Enter a prompt and wait for a complete result. | MRT2 fits real-time experiments and performance; prompt-to-track fits quick finished drafts. |
| Control inputs | MIDI, text, and audio together. | Usually text prompts plus limited structural controls. | MIDI lets the model respond to performance gestures. |
| Runtime location | Officially framed around local, open-weight, Apple Silicon apps and DAW plugins. | Often cloud-hosted services. | MRT2 is more natural for research, plugins, and local music-software integration, but it needs local hardware. |
| Output target | Continuous musical audio that can be steered. | Complete songs or complete clips. | MRT2 behaves more like a real-time instrument or accompanist than a finished-song factory. |
| Creative boundary | The model card focuses on instrumental music and notes non-lexical vocal-sound limitations. | Often marketed around vocal song generation. | MRT2 is best understood for instrumental, texture, accompaniment, and interactive music scenes. |
Key Facts From Official MRT2 Sources
| Dimension | Official source | Accurate reading |
|---|---|---|
| License | Code under Apache-2.0, model weights under CC-BY 4.0. | Not a single-license release; integrations should read code, weights, and usage terms together. |
| Model split | 2.4B base / 230M small. | Base and small reflect different quality and local-running tradeoffs. |
| Audio codec | SpectroStream converts 48kHz stereo audio into tokens at 25Hz frame rate, 64 RVQ depth, 10-bit codes, and 16kbps. | Real-time behavior comes from the model plus codec/streaming representation, not sample rate alone. |
| Control inputs | Text prompts, audio examples, and MIDI. | The three inputs represent style, context, and performance-state control. |
| Training data | Roughly 71k hours of stock music, mostly instrumental. | Expectations around vocal lyrics should be cautious; the model card notes vocal sounds tend to be non-lexical. |
| Evaluation | The model card says metrics and results will be shared in a forthcoming technical report. | Do not invent leaderboards or unpublished scores; cite only released architecture and limitations. |
What the release changes for interactive music
MRT2's keywords are continuous generation and low-latency control. It is designed to be played and steered, not only commanded by a prompt.
The model card centers interactive music creation and mostly instrumental stock music. Finished songs, lyrics, vocals, and release-ready production still need a human workflow.
Open weights and local inference make research, plugins, and DAW integration more practical, but hardware, buffers, host software, and audio interfaces all shape the experience.
All images and GIFs in this briefing are official Google Magenta release assets, not substitute drawings or recreated charts.