ChordEdit: one-step low-energy transport brings real-time image editing to TelkNet · TelkNet
Model
ChordEdit: one-step low-energy transport brings real-time image editing to TelkNet
ChordEdit is a CVPR 2026 Oral / Best Student Paper Honorable Mention paper. It reframes one-step text-guided image editing as a dynamic optimal transport problem between source and target prompts, then uses a Chord Control Field to reduce high-energy drift differences that distort objects and damage backgrounds. TelkNet now integrates ChordEdit as an in-site image editing tool with official-style source prompt, target prompt, seed, sample count, time-window, and step-scale parameters.
ChordEdit: one-step low-energy transport brings real-time image editing to TelkNet
News date: 2026-06-16
CVPR 2026 Oral
Best Student Paper Honorable Mention
Training-free / inversion-free / model-agnostic
ChordEdit image editing is available in the TelkNet tool catalog
Abstract
ChordEdit is a CVPR 2026 image-editing paper from Liangsi Lu, Xuhang Chen, Minzhe Guo, Shichu Li, Jingchao Wang, and Yang Shi. The paper studies a deceptively hard question: if one-step text-to-image models such as SD-Turbo can synthesize images quickly, why do training-free text-guided editors break when the same editing logic is forced into one large step?
The answer is not simply "one step is too few." ChordEdit argues that the naive edit direction is a high-energy, irregular control field. A direct drift difference between a source prompt and a target prompt can be tolerable when averaged across many denoising steps, but in the one-step regime it has no time to correct itself. The result is familiar to anyone who has tested fast image editing: objects warp, backgrounds break, identity drifts, and areas that should remain untouched become noisy.
ChordEdit reframes the edit as a dynamic optimal transport problem between the source and target prompt distributions. Its Chord Control Field acts as a time-smoothed, low-energy estimator of the editing direction, so a single large integration step becomes more stable. In TelkNet, users upload an image, describe the source image, describe the desired target edit, tune the official-style parameters, and receive a PNG result.
Official project figure: ChordEdit demonstrates real-image edits such as object, attribute, and season changes while preserving non-edited regions.
The Problem: Fast Generation Was Not Yet Fast Editing
The last few years of diffusion research created a strong expectation: if a model can generate an image in one or a few steps, then editing should also become instant. SD-Turbo, SwiftBrush-v2, InstaFlow, and related distilled generators all point toward interactive creation, where a user changes a phrase and sees a new visual state almost immediately. But editing a real image is a stricter task than generating a new one from noise. The model must change what the user asked to change while preserving everything else that still matters.
That second requirement is what makes one-step editing difficult. Multi-step editors can gradually steer an image while repeatedly correcting the path. Inversion-based methods can reconstruct a source image in latent space, then edit along a trajectory. Few-step methods can trade some speed for additional correction steps. A one-step training-free editor has far less room to recover from a bad direction. If the first and only direction is unstable, the output has no second chance.
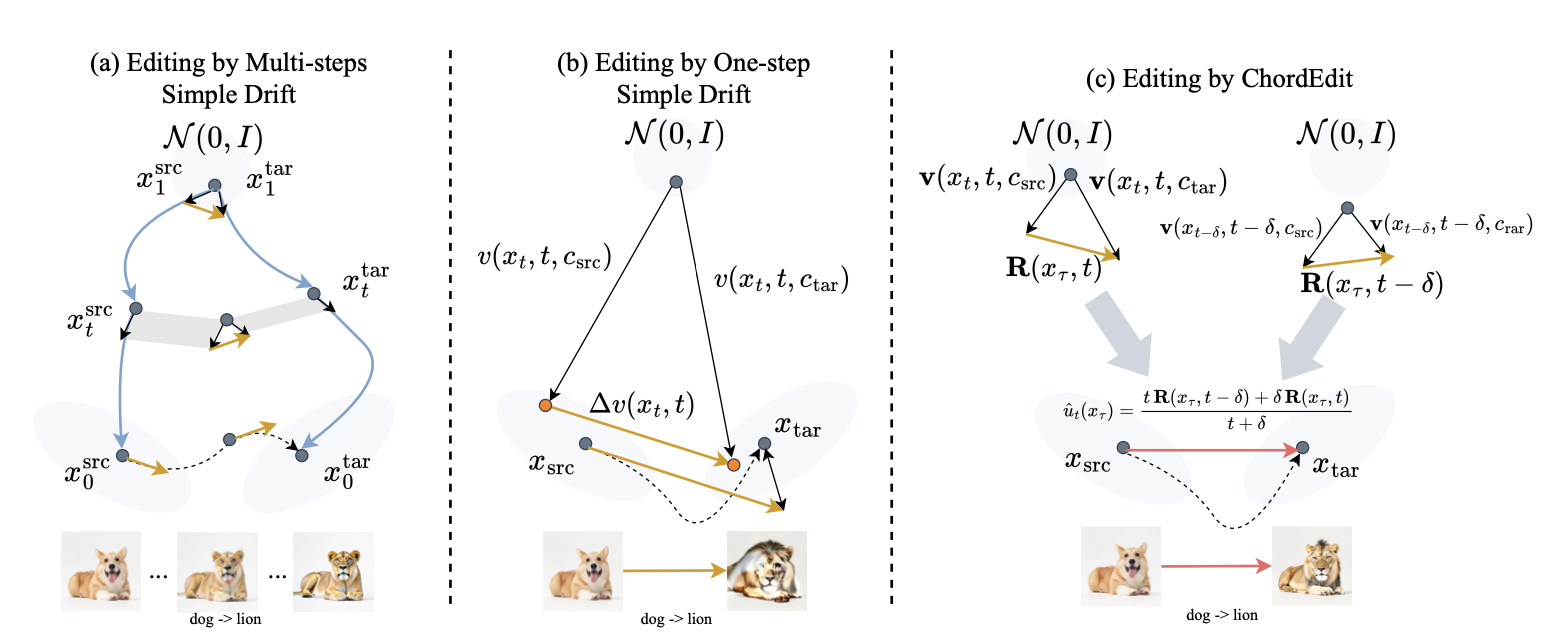
The ChordEdit paper describes this instability with the language of fields and energy. In simple drift editing, the model is queried under the source prompt and the target prompt, then the edit is approximated by subtracting the two drift fields. In a distilled one-step model, those fields can be highly nonlinear with respect to the prompt. Subtracting them can produce a large, erratic vector field. When that field is applied in one coarse step, the accumulated error shows up visually as object deformation, broken background structure, and spurious details.
This framing matters for product use because it explains why "just make it one step" is not enough. A tool can be fast and still unusable if it does not preserve the input image. The practical bar for image editing is not only prompt following; it is also consistency. If the user asks for a horse to become a unicorn, the surrounding scene should not melt. If the user asks for fall to become spring, the road layout should not be rebuilt. ChordEdit targets precisely this balance.
Official method figure: the naive one-step direction is high-energy and volatile, while the Chord Control Field smooths the observable editing field over time.
What ChordEdit Changes Conceptually
ChordEdit's central move is to stop treating editing as raw vector arithmetic between two prompt-conditioned fields. Instead, it asks what low-energy path would transport the source distribution toward the target distribution. The paper draws on the dynamic optimal transport view, especially the idea that among possible transport fields, a lower-energy path is more stable and less likely to create violent deviations.
In implementation terms, the method does not require retraining the underlying text-to-image model. It is training-free. It does not require an expensive per-image inversion step. It is inversion-free. It queries the model's velocity, noise prediction, or an equivalent observable field and constructs the edit control from those observations. That is why the authors describe it as model-agnostic: the same framework can be adapted to different fast T2I parameterizations by mapping their outputs into a comparable field space.
The key object is the Chord Control Field. Rather than use the instantaneous drift difference at one time, ChordEdit builds a time-weighted average over a short interval. This acts like a temporal smoothing operator. The field becomes lower energy and lower variance, which is exactly what a one-step integration needs. In plain language: the method takes a jittery, overreactive edit signal and turns it into a smoother chord that points toward the target without shaking the source image apart.
The paper also describes an optional proximal refinement step. The transport component prioritizes consistency and preservation. The refinement component can increase target semantic alignment. This separation is useful because real editing often needs two things at once: keep the original image recognizable, but make the requested edit visible enough that the task feels complete.
Why "Training-Free" And "Inversion-Free" Matter
A trained one-step editor can be fast, but it may depend on an extra model, an inversion network, a specific backbone, or a restricted data regime. That can be acceptable in a research prototype, but it reduces portability. A training-free editor is attractive because it can use a model the user or platform already has. An inversion-free editor is attractive because it avoids spending additional time reconstructing a source image before the edit even begins.
ChordEdit positions itself in the difficult corner where all three constraints meet: one-step, training-free, and inversion-free. This is a narrow target. Multi-step training-free methods can average away instability over time; inversion-based methods can anchor the image more carefully; training-based methods can learn a specialized correction. ChordEdit tries to preserve the portability of training-free editing while recovering enough stability for real-time use.
That distinction is also why TelkNet's integration is not a generic image-to-image wrapper. The tool exposes the source prompt and target prompt because the method needs both. It exposes the seed, noise sample count, transport start/end window, delta, and step scale because those are the meaningful controls from the official demo. The public tool interface mirrors the paper's editing model instead of hiding it behind a vague "magic edit" button.
How To Read The Reported Results
The ChordEdit paper evaluates on PIE-bench, comparing against multi-step, few-step, and one-step editors. The key metrics are not a single leaderboard number. Background consistency is measured with metrics such as PSNR, semantic alignment is represented by CLIP-Edited style scores, and runtime is reported because the whole point is real-time editing. The paper's claim is therefore a balance claim: ChordEdit aims to be fast while keeping enough fidelity and semantic strength to remain useful.
Several reported numbers are useful for interpreting the method. The conclusion states a runtime of 0.38 seconds and a low VRAM footprint. In the main comparison, the authors report that ChordEdit requires less than half the VRAM of SwiftEdit on the same model while remaining competitive in quality. They also report large speedups over multi-step methods, including about 19 times faster than FlowEdit and over 208 times faster than Direct Inversion, plus at least 3.4 times faster than the fastest few-step alternative in their comparison.
The ablations are more informative than the headline speed. Without the proximal refinement, the Chord field emphasizes preservation: the paper reports a PSNR of 23.89 and a CLIP-Edited score of 21.87 for the Chord transport variant, compared with 21.89 and 20.83 for the naive field in that setting. With the refinement, semantic alignment improves: on SD-Turbo, the reported naive baseline moves from PSNR 21.38 and CLIP-Edited 21.96 to ChordEdit's PSNR 22.20 and CLIP-Edited 22.96.
The cross-model table is also important. The paper reports improvements over the naive baseline on InstaFlow, SwiftBrush-v2, and SD-Turbo. For SD-Turbo specifically, it reports PSNR improving from 21.38 to 22.20 and CLIP-Edited from 21.96 to 22.96. That supports the authors' model-agnostic claim, but it should be read carefully: model-agnostic does not mean every model, prompt, and photo will behave identically. It means the method is formulated so it can be applied across compatible fast T2I backbones rather than being trained only for one fixed editing network.
Official energy visualization: the paper links high-energy naive fields with artifacts and background corruption, while ChordEdit produces lower-energy edits.
Comparison With Common Editing Routes
Route
What it optimizes
Typical cost
Where ChordEdit differs
Multi-step diffusion editing
Gradual correction, strong preservation, mature control methods.
Often many denoising steps, sometimes inversion, higher latency.
ChordEdit targets the one-step regime instead of relying on repeated correction.
Few-step accelerated editing
Lower latency while keeping several correction steps.
Still slower than one-step interaction and often model-specific.
ChordEdit tries to keep quality competitive while reducing the edit to a single transport step plus optional refinement.
Training-based one-step editing
Speed and learned correction for a particular route.
Extra training, specialized networks, and less model flexibility.
ChordEdit is training-free and uses the existing fast T2I model as a black box.
Naive one-step drift difference
Simple training-free edit direction.
High-energy field, object distortion, and background breakup.
ChordEdit replaces the instantaneous difference with a smoothed low-energy Chord Control Field.
Using ChordEdit In TelkNet
The workflow is direct: upload a JPEG, PNG, or WebP image; describe the source image; describe the desired target image; keep or adjust the official parameters; submit the edit; and download the generated PNG when it completes.
The parameter surface follows the official demo. Users provide source_prompt and target_prompt. The seed defaults to 42, matching the official demo default. The transport controls include t_start, t_end, t_delta, and step_scale. The sample count uses the official n_samples range of 1 to 16. TelkNet defaults this to 16 because the product requirement is to start from the highest-quality setting, while users can still lower it for faster experimentation.
How To Use It Well
Write the source prompt as a caption
ChordEdit needs a source prompt because it estimates a transport field between source and target conditions. Describe the image that is already present, not only the desired edit.
Keep the target edit specific
Good target prompts describe the intended semantic change without rewriting the whole scene. "A yellow taxi on snow" is usually safer than a long prompt that asks for many unrelated changes.
Use seed for comparison
Keeping the seed fixed makes parameter comparisons easier. Change the seed when exploring different plausible versions of the same edit.
Use high samples for final output
TelkNet defaults to the maximum official sample count. For quick tests, reduce it; for final runs, use the highest-quality default.
What The Method Does Not Promise
ChordEdit is fast and technically elegant, but it is not a universal photo editor. It does not understand unspoken user intent beyond the prompts. It cannot guarantee that every tiny identity cue, logo, face, or text string remains unchanged. It can reduce the instability of naive one-step editing, but it does not remove all model bias, all hallucination, or all prompt ambiguity. The paper itself notes potential misuse and frames the method for creative and assistive applications.
Users should also separate three things: paper performance, official demo behavior, and real editing results. Paper performance is measured under benchmark protocols. The official demo shows what the authors intended to expose. Real results still depend on the input image, prompts, seed, and parameter choices. These layers are aligned, but they are not identical to a controlled paper table.
The best practical reading is this: ChordEdit makes real-time text-guided editing more plausible because it attacks the specific instability of one-step control fields. It is especially relevant when the user wants semantic edits with strong background preservation, and when latency matters enough that traditional multi-step editing feels too slow.
Facts, Interpretation, And Product Meaning
Item
Paper or official fact
How TelkNet interprets it
Publication status
The project page marks ChordEdit as CVPR 2026 Oral and Best Student Paper Honorable Mention; arXiv lists it as accepted by CVPR 2026.
Important enough for a full article, but still explained through user-facing tool value rather than prestige alone.